To go alongside the first proper release of my NSF ODP Tooling, I've added an example project to the Git repository:
https://github.com/OpenNTF/org.openntf.nsfodp/tree/master/example
This project demonstrates how to use the tooling to create an XPages library project and build an NSF that uses it within the same Maven tree. This example project also serves as a reasonable template for the standard kind of project setup I make for Domino nowadays, minus a compile-time test plugin (which I'll probably add in eventually).
Environment Setup
Before building the ODP, you'll need to set up a compilation server and configure Maven to know about it. To start out with, make sure you have a Notes-ified Maven environment as described here. Since the IBM-provided update site is quite old at this point, it may be worth updating it from your local installation.
Next, install the Domino plugins on a Domino server running at least 9.0.1 FP10. It's best to do this on a pristine server without non-standard plugins installed, since part of the compilation process is to load and unload the needed plugins for your project. For my needs, I set up a Linux VM and it's doing the job nicely. Once that's set up, configure your Maven settings.xml to reference your compiler server, merging these values in with the normal Notes properties:
<?xml version="1.0"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<profiles>
<profile>
<id>main</id>
<properties>
<notes-platform>file:///Users/jesse/Documents/Java/IBM/Notes9.0.1fp10</notes-platform>
<nsfodp.compiler.server>someserver</nsfodp.compiler.server>
<nsfodp.compiler.serverUrl>http://some.server/</nsfodp.compiler.serverUrl>
</properties>
</profile>
</profiles>
<activeProfiles>
<activeProfile>main</activeProfile>
</activeProfiles>
<servers>
<server>
<id>someserver</id>
<username>builduser</username>
<password>buildpassword</password>
</server>
</servers>
</settings>
Note the "server" block at the bottom to provide login credentials. The plugins require a non-anymous user - at the moment, they allow ANY non-anonymous user, though, so you can create a new user just for compilation purposes. It's also good practice to encrypt your server connection passwords.
There are also options for deploying the NSF, but, since that's less important for our needs, I'll leave that aside for now. The README has a bit more information about that.
The Example Project
The structure of the projects is similar to the one I detailed in my Java series a couple of years back, but it's evolved a bit since then. The main aspects of it of note are:
The Folder Structure
Lately, I've been following the advice from the Vogella blog about how to structure an OSGi project. In a case like this, where there is only one plugin, one feature, and one update site, it's overkill, but I've found it to be better to create this structure at the start so you don't end up with a big mess of projects serving different needs within the same flat folder.
The nsfodp-maven-plugin
The most pertinent addition is the ODP wrapped in a Maven project. In the nsfs/nsf-example folder, I created a pom.xml to configure a project of type domino-nsf, which expects by default the ODP to be in an odp folder immediately within it. The ODP in there is entirely normal: it's just a near-fresh NSF exported from Designer, with the main addition being the inclusion of the XPages Library.
The project's pom does a few things: it establishes it as being a domino-nsf project and it adds some additional configuration to the nsfodp-maven-plugin, telling it to include the update site generated earlier in the build as part of the compilation process; this is what allows the NSF to build with the XPages library in the current project.
License Management
Since I've been making contributions for OpenNTF and particularly since taking over as IP manager, I've developed a much better appreciation for dotting my is and crossing my ts when it comes to licensing. One of the tools I quite like for this is the license-maven-plugin from com.mycila (it's not the only one of that name, and any of them should do the job). This plugin allows you to specify a license header template to be added to the top of each of your source files, which is an otherwise-tedious task that's easy to neglect. Once I added that to the root pom and set up appropriate exclusions (definitely make sure to add exclusions for any third-party code!), I'm able to run mvn license:format from the root project and have it run through all the source files in the directory tree and add an appropriately-formatted license header. I've definitely made this a standard part of my project setup now.
Plugin Versioning and maven-enforcer-plugin
This one admittedly doesn't have that much impact on day-to-day development, but it's another good "keeping your ducks in a row" addition: I've taken to explicitly specifying the versions for my Maven plugins, even when the version is implied by the core Maven version. This "locking down" can reduce one cause of mysterious code breaking if an implicit inclusion is upgraded in a way that is incompatible with your build process.
My friend in this task is the versions-maven-plugin's versions:display-plugin-updates goal, which will look through your project tree and find plugins that have newer versions in the available repositories and also tell you what your implied plugin versions are from the super-pom. I use this information to explicitly enumerate the plugins and find updates - the "copy and paste this block of XML" nature of Maven means that it's very easy to end up running a plugin that's several major versions behind.
Alongside this, the goal will tell you what the minimum required Maven version is for everything you're doing, which I've taken to specifying in the old-style prerequisites block as well as via the newer-style maven-enforcer-plugin route. Laying out these requirements explicitly is another good way to avoid phantom problems. Note that, for Eclipse, it's good to add a m2e configuration block to ignore the enforcer line, since m2e doesn't know what to do with it.
The OpenNTF Artifactory Server
This isn't so much a new technique as it is a prerequisite for using the plugin: currently, the plugin is hosted on OpenNTF's Artifactory server and not Maven Central, so you'll have to add a pluginRepository block for it. Once you have that, you can add the nsfodp-maven-plugin to the root pom.
The Eclipse Tooling
Once you have a project configured in Maven, the next step is to install the Eclipse tooling. This can be installed into any Eclipse installation running Neon or newer in a Java 8+ JVM. For my use nowadays, I primarily use Oxygen.3a on the Mac, but any platform should work.
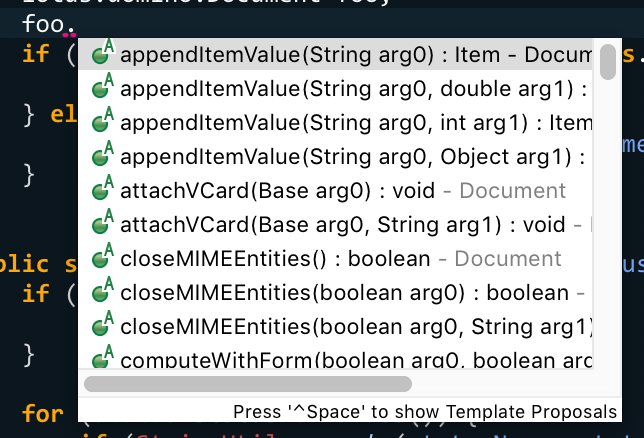
Once you have that installed, you can import the projects into your Eclipse workspace and the tooling will adapt some elements for use as a pseudo plugin project. It will auto-generate MANIFEST.MF and build.properties files at the project's top level (which is why it's important to have the ODP in a sub-directory, so the FP10+ MANIFEST.MF isn't overwritten) and use those to configure the XPages Java class path, requiring the same plugins as the NSF does, including XPages library plugins, as well as adding any used Jars to the classpath. The result is that you can use it to edit your Java code with full classpath knowledge:
Beyond that, it provides some autocomplete capabilities for editing .xsp files. Currently, it had built-in knowledge of the controls that come standard on a Domoino 9.0.1FP10 server, plus any custom controls in your application. This autocomplete takes the form of contributions to Eclipse's standard XML editor, so it's pretty snappy:
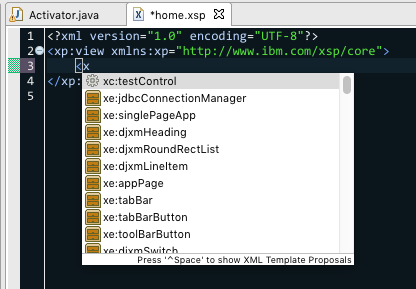
This works for tag names as well as component properties.
Limitations
This tooling has some significant limitations:
- The biggest is that it doesn't have any special knowledge of most design elements - and, if you use binary DXL for safety purposes, that means that most legacy elements are difficult to modify.
- It doesn't currently do any programmatic pairing between editable design elements and their associated
.metadata and .xsp-config files, so it's best to do keep Designer around for creating those.
- The XSP autocomplete consists just of contributions to the autocomplete list, and so it doesn't do any checking for legality of content or tag placement, nor does it currently have any descriptive metadata.
Future Prospects
I've gotten this project to a point where I can reduce my level of daily annoyance with my tools, which is an important step. There are a few more things that I'd like to add so I can further reduce my need to use Designer at all: giving the editors some knowledge of split files could allow for manipulating custom control properties in a better way, some property panes may be worth making, I'd like to have a way to modify binary-format DXL notes (which may either be by using ODA's CD structure implementation or by round-tripping the DXL to Domino to convert it to friendly format for editing), and I'd like to eliminate the strict requirement of having a Domino server around for compilation.
The last one is a fun project on its own: my plan is to have a headless Java app loading up an Equinox environment and using the same plugins and REST services as the Domino server. That's mostly functional now, but it has some odd compilation-time bugs that will take some investigation. With that in place, it'd remove the need for any separate server, though it would then require that your development environment have a Notes or Domino runtime available.
As always, I'd welcome any contributions, especially if someone has a particular itch they'd like to scratch. I have some open issues in the GitHub project that I likely want to tackle at some point, and I'm sure this could cover a lot more ground besides.