Adding Load Balancing to the nginx Setup
Sat Sep 20 11:00:45 EDT 2014
- Sep 18 2014 - Setting up nginx in Front of a Domino Server
- Sep 20 2014 - Adding Load Balancing to the nginx Setup
- Sep 22 2014 - Arbitrary Authentication with an nginx Reverse Proxy
- Sep 24 2014 - Domino and SSL: Come with Me If You Want to Live
In an earlier post, I went over the basic setup of installing nginx on a single Domino server to get the basic benefits (largely SSL). Next, it's time to expand the setup to have one nginx server in front of two Domino servers.
The concept is relatively straightforward: when an HTTP request comes in, nginx will pick one of the back-end servers it knows about and pass the request along to that. That allows for balancing the load between the two (since the act of processing the request is much more expensive than the proxying, you need far fewer proxies than app servers), as well as silent failover if a server goes down. The latter is very convenient from an administrative perspective: with this setup, you are free to bring down all but one Domino server at any time, say for maintenance or upgrades, without external users noticing.
The main complication in this phase is the handling of sessions. In the normal configuration, nginx's load balancing is non-sticky - that is to say, each request is handled on its own, and the default behavior is to pick a different server. In some cases - say, a REST API - this is just fine. However, XPages have server-side state data, so this would completely mess that up (unless you do something crazy). There is a basic way to deal with this built-in, but it's not ideal: it's "ip_hash", where nginx will send all requests from a given IP to the same back-end. That's more or less okay, but would run into problems if you have an inordinate number of requests from the same IP (or same-hashed sets of IPs). So to deal with this, I use another layer, a tool called "HAProxy". But first, there'll be a bit of a change to note in the Domino setup.
Domino
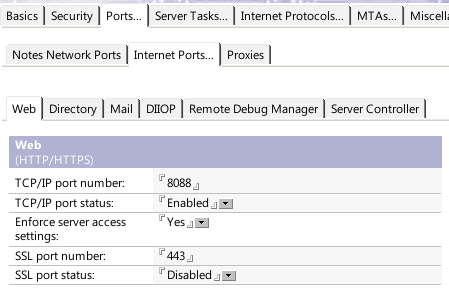
Since we'll now be balancing between two Domino servers, the main change is to set up a second one. It's also often a good idea to split up the proxy and app servers, so that you have three machines total: two Domino servers and one proxy server in front. If you do that, it's important to change the HTTP port binding from "localhost" to an address that is available on the local LAN. In my previous screenshot, I did just that. You can also change HTTP back to port 80 for conceptual ease.
In my setup, I have two Domino servers named Terminus and Trantor, available on the local network as terminus-local and trantor-local, with Domino serving HTTP on LAN-only addresses on port 80.
HAProxy
HAProxy is a very lightweight and speedy load balancer, purpose-built for this task. In fact, with the latest versions, you could probably use HAProxy alone instead of nginx, since it supports SSL, but you would lose the other benefits of nginx that will be useful down the line. So my setup involves installing HAProxy on the same server as nginx, effectively putting it in place of the Domino server in the previous post.
Much like nginx, installing HAProxy on Ubuntu/Debian is easy:
# apt-get install haproxy
The configuration is done in /etc/haproxy/haproxy.cfg. Most of the defaults in the first couple blocks are fine; the main thing to do will be to set up the last block. Here is the full configuration file:
global
maxconn 4096
user haproxy
group haproxy
daemon
defaults
log global
mode http
option httplog
option dontlognull
retries 3
option redispatch
maxconn 2000
contimeout 5000
clitimeout 500000
srvtimeout 500000
listen balancer 127.0.0.1:8088
mode http
balance roundrobin
cookie balance-target insert
option httpchk HEAD /names.nsf?login HTTP/1.0
option forwardfor
option httpclose
server trantor trantor-local:80 cookie trantor check
server terminus terminus-local:80 cookie terminus check
The listen block has HAProxy listening on the localhost address (so external users can't hit it directly) on port 8088 - the same settings as the local Domino server used to be, so the nginx config from before still applies.
The session-based balancing comes in with the balance, cookie, and server lines. What they do is tell HAProxy to use round-robin balancing (choosing each back-end in turn for a new request), to add a cookie named "balance-target" (could be anything) to denote which back-end to use for future requests, and to know about the two servers. The server lines give the back-ends names, point them to the host/post combinations on the local network, tell them to use cookie values of "trantor" and "terminus" (again, could be anything), and, presumably, to perform the HTTP check from above (I forget if that is indeed what "check" means, but it probably is).
The httpchk line is what HAProxy uses to determine whether the destination server is up - the idea is to pick something that each back-end server will respond to consistently and quickly. In Domino's case, doing a HEAD call on the login page is a safe bet (unless you disabled that method, I guess) - it should always be there and should be very quick to execute. When Domino crashes or is brought down for maintenance, HAProxy will notice based on this check and will silently redirect users to the next back-end target. Any current XPage sessions will be disrupted, but generally things will continue normally.
And that's actually basically it - by shimming in HAProxy instead of a local Domino server, you now have smooth load balancing and failover with an arbitrary number of back-end servers. The cookie-based sessions mean that your apps don't need any tweaking, and single-server authentication will continue to work (though it might be a good idea to use SSO for when one back-end server does go down).
There is actually a module for nginx that does cookie-based sticky sessions as well, but the stock Ubuntu distribution doesn't include it. If your distribution does include it - or you want to compile it in from source - you could forgo the HAProxy portion entirely, but in my experience there's no great pressure to do so. HAProxy is light enough and easy enough to configure that having the extra layer isn't a hassle or performance hit.